Introduction
The RDF toolkit for Rust is a set of crates providing the ability to work with RDF data. The goal is to provide a consistent set of tools for reading and writing files, manipulating models programmatically, and working with graph (triple) stores.
Goals
- Usability
- Avoid lifetimes in public structures
- Consistency
- As Rust-like as possible
- Correctness Sensible standards conformance
- Flexibility
Not Goals
- Performance; in terms of implementation, the primary goals of the RDFtk project is to provide a consistent and complete set of crates for handling RDF data. To this end the crates will value readability and usability over runtime optimization (either memory, or speed) at this time. Getting the right interface will be the primary aim with those optimizations coming as necessary.
- Productization
![]()
![]()
![]() |
|
![]()
![]()
![]()
All usage of the W3C Semantic Web Technology Buttons are in accordance with W3C Semantic Web Logos and Policies.
RDF Primer
RDF is a data model for describing things in a manner that allows for open extension, easy merging of data, built on the same concepts as the web itself and which allows for the inference of facts from those asserted. This data model is abstract in the sense that it is described entirely based upon its semantics and not on its syntax. Multiple serialization forms, representations, are described for RDF data but none describe RDF itself.
This brief primer introduces enough to get started on understanding the RDFtk set of crates and more details will be introduced in crate-specific sections. There is a more complete W3C RDF Primer that has a lot more information than presented here.
Data Modeling

- Data Modeling - ER
- Software Modeling - UML
- Data Schema - SQL, XSD, ...
- Classes
CREATE TABLE authored (
author VARCHAR(128) NOT NULL,
thing VARCHAR(128) NOT NULL
);
INSERT
INTO authored (author, thing)
VALUES ('Simon', 'this');
#![allow(unused_variables)] fn main() { struct Authored { pub author: String, pub thing: String, } fn make_one() -> Authored { Authored { author: "Simon", thing: "this" } } }
CREATE TABLE author (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(128) NOT NULL
);
CREATE TABLE authored (
author INT NOT NULL,
thing VARCHAR(128) NOT NULL,
FOREIGN key(author) REFERENCES author(id)
);
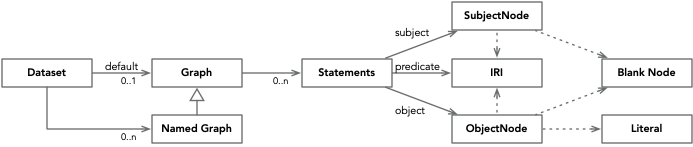
Resources, Statements, and Literals
The data model for RDF is surprisingly simple, the core component of which is the Statement. A statement asserts a fact based on the linguistic form subject predicate object (property will sometimes be used instead of the more formal predicate). Examples might be:
- Simon authored this
- <https://github.com/johnstonskj/rust-rdftk.git> is-a repository
- <http://crates.io/crates/rdftk_core> description “The core data model.”
This structure can be more formally described as:
- The Subject of a statement is a Resource which is either addressed with an IRI (Internationalized Resource Identifiers), or an internally generated identifier commonly known as a Blank Node.
- The Predicate is some relationship between the subject and object and is always an IRI.
- The Object of a statement is either a resource or a Literal. In the case of a resource the same details apply as for the subject.
- A Literal is a string value that may have an associated Language or Data Type but not both.
- The language will be expressed as an ISO language identifier, “en”, “en_us”, etc.
- The data type will be expressed as an IRI usually to one of the defined XML Schema Data Types or a type expressed in XML Schema.
Due to the three parts in each statement a statement may be referred to as a Triple.
A collection of statements is a Graph, and if this graph itself is addressable (has an IRI itself) it is termed a Named Graph. This inherently graph nature means that RDF stores and graph stores such as AWS Neptune are a great match.
Visually
It is common in RDF documents to see diagrams representing a statement such as that below. The predicate will be shown as a directed, and annotated, arrow from subject to object. This is similar to Chen’s notation for entity–relationship modeling, and as such demonstrates RDF’s natural style in describing data.
It is important to note that all predicates are directional implying that a bi-directional, or Symmetric relationship requires two predicates -- see Vocabulary Descriptions below.

To visually distinguish between named resources, blank nodes, and literals, the following conventions will be used.
- Named resources will be shown as large ovals, their inner name is some short form of the resource’s IRI.
- Blank nodes will be shown as small ovals usually with no inner name (as they are effectively anonymous).
- Literals will be shown as rectangles; their content may, or may not, be shown in double quotes.

The following is a pretty good representation of the complete RDF data model, hopefully most of which will be clear by the end of this primer.
An Annotated Example
As a simple, and easy to approach, example let us consider the Cargo.toml file for the core crate. This is a set of
facts stated about a Cargo crate, and we will work up to an RDF representation of it.
[package]
name = "rdftk_core"
version = "0.1.10"
authors = ["Simon Johnston <johnstonskj@gmail.com>"]
edition = "2018"
description = "The core data model."
documentation = "https://docs.rs/rdftk_core/"
repository = "https://github.com/johnstonskj/rust-rdftk.git"
license = "MIT"
readme = "README.md"
publish = true
[dependencies]
error-chain = "0.12.2"
unique_id = "0.1.3"
rdftk_iri = { version = "0.1.2", path = "../rdftk_iri" }
rdftk_names = { version = "0.1.5", path = "../rdftk_names" }
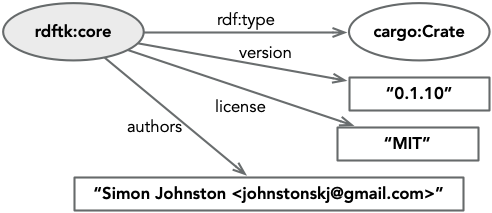
First, let’s start with a single statement, we will assert that a resource, identified as rdftk:core, is related to
a resource, identified as cargo:crate, with the relationship rdf:type. The astute reader will notice that these
names appear to be namespaced, type in the namespace rdf for example, and this is true. Namespaces, or vocabularies,
are described below. Note, the shading of the subject node in this case is simply to anchor the examples, it has no
additional meaning.

Given this simple start we can begin adding other attributes from the package section of the file. These additional properties are literal values, so they have been drawn as rectangles. In this primer we will always show literal values in quotes, this is not necessary but adds clarity.
When we get to the attribute publish however we want to express that this is a boolean value and not just a string.
To do this we add a data type from the XML Schema Datatypes (XSD) standard to the literal value, as shown below.

This kind of type annotation can also be applied to a resource, if that resource has an rdf:type predicate, thus
saving an arrow in the diagram. The different forms of annotation can be seen in the following figure. As it is common
to not show the identifier for a blank node the annotation is the only value shown.

Sometimes we want to have a resource with multiple predicates, but without the strong identity of an IRI. To do this
we use blank nodes, nodes that have an internally generated, and therefore not externally addressable, identity. For
example, we could choose to break up the string value for the authors property into separate name and email, but don’t
want to give this representation an IRI.

However, the actual attribute authors is a TOML list, and we have just added a single predicate relationship. In RDF
it is perfectly reasonable, and frankly quite common, to simply allow multiple predicate instances.
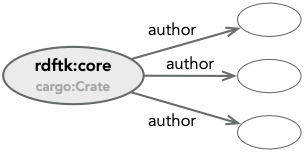
However, what is the semantic meaning of this? are these all authors, is there implied ordering? To this end RDF has a number of collection structures, List, Sequence, Alternatives, and Bag that model linked lists, ordered lists, a list of alternatives, and an unordered collection. For a good description of RDF collections, see the blog post Ordered Data in RDF.
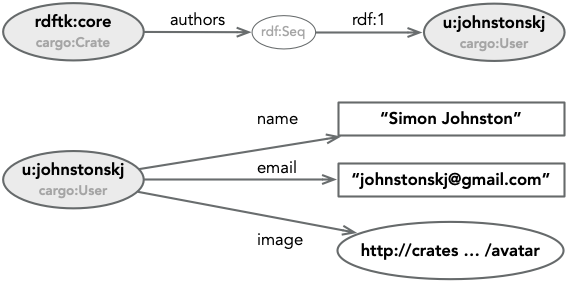
For our example, we choose to model the authors attribute as an RDF sequence, the sequence itself is a blank node
containing other blank nodes from the previous author example.

Finally, the real power of the RDF data model is that both subject and object can be resources, and in particular named
resources, and we can therefore link statements via these. For example; let us assume that the crates.io site also
describes users in RDF, now we can model our author predicate to either a blank node as shown above, or a named
user by using their IRI. In this example the two sub-graphs are managed by different services, but the ubiquitous use
of the IRI as an identifier means the two are inherently linked.
This is an important consideration as RDF adheres to the Open-World Assumption the implication of which is that the same IRI may be the subject of a sub-graph elsewhere, and that the graphs may in fact contradict each other.
Statements about Statements
A great advantage of both the flexibility of the RDF data model, and the open-world assumption, is that we can make statements about other statements. Why is this useful? Think about the following “Joe said, Jane said something“, Joe is the subject of a statement, “said” is the predicate, but the object is a statement; in this case we can infer that this is second-hand information. This means that both data and metadata as well as data and provenance information can all be described in the same language and at the same level (no getting lost in meta- and meta-meta- languages).
So, let’s take a look at at how this works, because if we look at figure 1.12 you can see we have an issue, how do we attach the outer said predicate to complete inner statement?
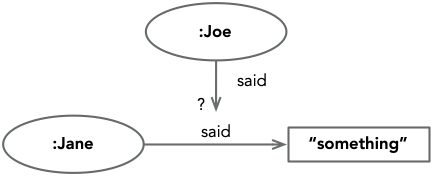
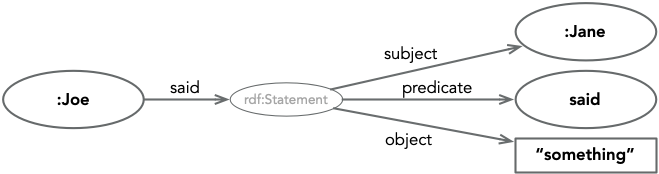
The answer is a procedure called Reification (which the dictionary describes as to consider or represent (something abstract) as a material or concrete thing) that turns a single statement into an entity on it’s own. To accomplish this, simply follow these steps:
- Create a new blank node as the subject for the following.
- Create a statement with the predicate
rdf:typeand objectrdf:Statement. - Create a statement with the predicate
rdf:subjectand object being the original statement’s subject. - Create a statement with the predicate
rdf:predicateand object being the original statement’s predicate. - Create a statement with the predicate
rdf:objectand object being the original statement’s object.
With this in place we can create new statements whose object is the new blank node, as shown below.
Representations
As mentioned above, RDF does not dictate a representational form, although the early RDF specifications used XML as an example or canonical form. Today there are a number of common representations with RDF/XML, JSON-LD, NT/NQ, N3, and Turtle/Trig being the most common. Some vocabularies have their own specific representational forms, but that is outside our scope here. Most of the examples in this document will use Turtle (Terse RDF Triple Language), but we will take our last example from Joe and Jane and show some different forms.
In RDF/XML:
<?xml version="1.0" encoding="utf-8" ?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ns0="http://example.org/actions/">
<rdf:Description rdf:about="http://example.org/peeps/Joe">
<ns0:said>
<rdf:Statement>
<rdf:subject rdf:resource="http://example.org/peeps/Jane"/>
<rdf:predicate rdf:resource="http://example.org/actions/said"/>
<rdf:object>something</rdf:object>
</rdf:Statement>
</ns0:said>
</rdf:Description>
</rdf:RDF>
In RDF/JSON:
{
"http://example.org/peeps/Joe": {
"http://example.org/actions/said": [
{
"type": "bnode",
"value": "_:genid1"
}
]
},
"_:genid1": {
"http://www.w3.org/1999/02/22-rdf-syntax-ns#type": [
{
"type": "uri",
"value": "http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement"
}
],
"http://www.w3.org/1999/02/22-rdf-syntax-ns#subject": [
{
"type": "uri",
"value": "http://example.org/peeps/Jane"
}
],
"http://www.w3.org/1999/02/22-rdf-syntax-ns#predicate": [
{
"type": "uri",
"value": "http://example.org/actions/said"
}
],
"http://www.w3.org/1999/02/22-rdf-syntax-ns#object": [
{
"type": "literal",
"value": "something"
}
]
}
}
In JSON-LD:
[
{
"@id": "_:b0",
"@type": [
"http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement"
],
"http://www.w3.org/1999/02/22-rdf-syntax-ns#subject": [
{
"@id": "http://example.org/peeps/Jane"
}
],
"http://www.w3.org/1999/02/22-rdf-syntax-ns#predicate": [
{
"@id": "http://example.org/actions/said"
}
],
"http://www.w3.org/1999/02/22-rdf-syntax-ns#object": [
{
"@value": "something"
}
]
},
{
"@id": "http://example.org/actions/said"
},
{
"@id": "http://example.org/peeps/Jane"
},
{
"@id": "http://example.org/peeps/Joe",
"http://example.org/actions/said": [
{
"@id": "_:b0"
}
]
},
{
"@id": "http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement"
}
]
<http://example.org/peeps/Joe> <http://example.org/actions/said> _:B1 .
_:B1 <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement> .
_:B1 <http://www.w3.org/1999/02/22-rdf-syntax-ns#subject> <http://example.org/peeps/Jane> .
_:B1 <http://www.w3.org/1999/02/22-rdf-syntax-ns#predicate> <http://example.org/actions/said> .
_:B1 <http://www.w3.org/1999/02/22-rdf-syntax-ns#object> "something" .
N-Triples are a very raw form of the data in a line-oriented form that isn’t terribly readable. On the other hand it is easy and fast to parse and so tends to be used for data extract/load operations.
@prefix ns0: <http://example.org/actions/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
<http://example.org/peeps/Joe> ns0:said [
a rdf:Statement ;
rdf:subject <http://example.org/peeps/Jane> ;
rdf:predicate ns0:said ;
rdf:object "something"
] .
You can experiment with some of these representations using the online EasyRdf Converter.
Vocabulary Descriptions
While the term Schema is often used in conjunction with RDF the term is problematic for software folks as it has unfortunate connotations. For example, a database schema restricts the data that exists within its tables, a class in a programming language restricts the shape of instances. In both of these cases the schema has a closed-world assumption that it can validate the shape of things and that no things exists outside of schema control.
Common Vocabularies
The following are a number of vocabularies often used when making statements, or used to develop our own vocabularies.
- RDF itself (used below).
- RDF Schema the original way to describe RDF vocabularies (used below).
- XML Schema Datatypes not truly and RDF vocabulary but adopted as the data type specification for RDF literals (used below).
- OWL the web ontology language is a much more complete way to describe vocabularies ands uses parts of RDF Schema but goes way beyond it in terms of its ability to support inferencing.
- Dublin Core A commonly used vocabulary for defining metadata and annotations (used below).
- FOAF: Friend of a Friend an older vocabulary used to create network of social connections.
- PROV-O The PROV Ontology A vocabulary for asserting provenance about subjects.
- SKOS A vocabulary for the development of thesauri.
Example Vocabulary Mapping
Below is a mapping from the TOML file (left two columns) to predicates we will reuse or invent.
| Section | Attribute | Predicate | Restriction |
|---|---|---|---|
| package | name | dcterms:identifier | |
| version | semver:version | ||
| authors | dcterms:contributor | multiples | |
| author/name | foaf:name | ||
| author/email | foaf:mbox | ||
| author/image | foaf:depiction | ||
| edition | cargo:edition | ||
| description | dcterms:description | ||
| documentation | crate:documentation | ||
| repository | crate:repository | ||
| license | dcterms:license | ||
| readme | cargo:readme | ||
| publish | cargo:publish | ||
| features | dcterms:has_part | blank node | |
| name | dcterms:identifier | ||
| parts | dcterms:requires | rdf:Bag | |
| dependencies | dcterms:requires | blank node | |
| name | dcterms:references or dcterms:identifier | ||
| version | semver:matches | ||
| path | cargo:path |
Note that we use
foaf:name,foaf:mbox, andfoaf:depictionfor modeling our user, one might also use the PROV-O Person class which also has a name and email address. Which to choose sometimes becomes a bit of guesswork, but often depends on any additional semantics one gets with the parts of a vocabulary we decide to use. In this case FOAF has a lot less semantics than PROV-O for this problem. On the other hand PROV-O is exactly intended to solve our “Joe said...“ example above.
In the table above we used two new namespaces cargo:, and semver:, the following listing is the RDF Schema for
the Cargo vocabulary we have introduced so far. Note that while we assert that the new entity cargo:Crate is a
(the value a in this representation is a shortcut for the property rdf:type) rdfs:Class we do not make assertions
about the type of the remaining entities. This is where the RDF entailment comes in, the predicates rdfs:domain and
rdfs:range both have an assertion that rdfs:domain is rdfs:Property and therefore edition to readme must be
properties.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix cargo: <http://crates.io/rdf/cargo#> .
<http://crates.io/rdf/cargo#>
# Properties about the vocabulary itself.
dcterms:issued "2020-12-02"^^<http://www.w3.org/2001/XMLSchema#date> ;
dcterms:title "Cargo crate vocabulary."@en .
cargo:Crate
a rdfs:Class ;
rdfs:isDefinedBy <http://crates.io/rdf/crates#> ;
rdfs:label "A Crate resource"@en .
cargo:edition
rdfs:isDefinedBy <http://crates.io/rdf/crates#> ;
rdfs:label "Rust Edition"@en ;
rdfs:domain cargo:Crate ;
rdfs:range xsd:gYear .
cargo:documentation
rdfs:isDefinedBy <http://crates.io/rdf/crates#> ;
rdfs:label "URL for documentation."@en ;
rdfs:domain cargo:Crate ;
rdfs:range rdfs:Resource .
cargo:repository
rdfs:isDefinedBy <http://crates.io/rdf/crates#> ;
rdfs:label "URL for source repository."@en ;
rdfs:domain cargo:Crate ;
rdfs:range rdfs:Resource .
cargo:localPath
rdfs:isDefinedBy <http://crates.io/rdf/crates#> ;
rdfs:label "Local path for dependency resolution."@en ;
rdfs:domain cargo:Crate ;
rdfs:range rdfs:Literal .
cargo:publish
rdfs:isDefinedBy <http://crates.io/rdf/crates#> ;
rdfs:label "Whether to publish this crate."@en ;
rdfs:domain cargo:Crate ;
rdfs:range xsd:boolean .
cargo:readme
rdfs:isDefinedBy <http://crates.io/rdf/crates#> ;
rdfs:label "Path, relative to crate root, for a readme resource."@en ;
rdfs:domain cargo:Crate ;
rdfs:range rdfs:Literal .
Output Serialization
Here is the complete version of the RDF representation of our crate’s metadata. Note that we do not have a type asserted
for the subject which can be implied to be cargo:Crate given that it is the rdfs:domain of some of the asserted
properties.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix dcterms: <http://purl.org/dc/terms/> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix cargo: <http://crates.io/rdf/cargo#> .
@prefix semver: <http://crates.io/rdf/semver#> .
<http://crates.io/crates/rdftk_core>
dcterms:identifier "rdftk_core" ;
dcterms:version "0.1.10" ;
dcterms:contributor [
foaf:name "Simon Johnston" ;
foaf:mbox "johnstonskj@gmail.com" ;
foaf:depiction <http://crates.io/u/johnstonskj/avatar>
] ;
cargo:edition "2018"^^xsd:gYear ;
dcterms:description "The core data model." ;
cargo:documentation <https://docs.rs/rdftk_core/> ;
cargo:repository <https://github.com/johnstonskj/rust-rdftk.git> ;
dcterms:license "MIT" ;
cargo:readme "README.md" ;
cargo:publish "true"^^xsd:boolean ;
dcterms:requires [
rdf:type rdf:Bag ;
rdf:_1 [
dcterms:references <http://crates.io/crates/error-chain> ;
semver:matches "0.12.2"
] ;
rdf:_2 [
dcterms:references <http://crates.io/crates/unique_id> ;
semver:matches "0.1.3"
] ;
rdf:_3 [
dcterms:references <http://crates.io/crates/rdftk_iri> ;
semver:matches "0.1.2" ;
cargo:localPath "../rdftk_iri"
] ;
rdf:_4 [
dcterms:identifier "rdftk_names" ;
semver:matches "0.1.5" ;
cargo:localPath "../rdftk_names"
]
]
.
Query
SPARQL is the query language for RDF, and hopefully if you’ve seen SQL, and followed along with this primer so far, the following example should be pretty easy to follow. As there are no tables and columns the specifics of query matching are different and make use of basic graph patterns (BGP)s to match statements within a graph. The structure of these patterns is very similar to the syntax we’ve seen for Turtle, but include variables, identifiers that start with “?” or “$”. These variables not only determine what is included in the projection but also how graph patterns will be matched.
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT ?id ?descr ?ver
WHERE {
?s dcterms:identifier ?id ;
dcterms:description ?desc ;
dcterms:version ?ver .
} LIMIT 100
In this example the variable ?s is not returned in the projection, however its position in the match denotes the fact
that the identifier, description, and version all have the same subject regardless of what it is.
SPARQL has a number of query forms not just
SELECT;CONSTRUCTreturns a single RDF graph specified by a graph template,ASKto test whether or not a query pattern has a solution, andDESCRIBEwhich returns processor-dependent information on the resources required to complete a query.
The FROM clause in SPARQL identifies a graph to scope a query, and multiple graphs can be specified to produce results
across them.
PREFIX dcterms: <http://purl.org/dc/terms/>
SELECT ?id ?descr ?ver
FROM <https://crates.io/rdf/crates/>
WHERE {
?s dcterms:identifier ?id ;
dcterms:description ?desc ;
dcterms:version ?ver .
} LIMIT 100
A number of SPARQL tutorials exist, and the SPARQL specification itself has many good examples.
Update
TBD
Extensions
The following are some commonly used extensions to RDF, some of which may of course be a part of future standards versions.
Quads
One issue with RDF is that, in general, the representations do not carry with them any identifier of the graph, or
context, from which they came. Graphs and Datasets (collections of graphs) are a part of the broader RDF data model
but this information can be lost along the way. Consider the following subset of our example Cargo file from above. We
know, because we designed it, that these statements exist in the crates graph <https://crates.io/rdf/crates/> but how
would you know from looking at this?
<http://crates.io/crates/rdftk_core>
<http://purl.org/dc/terms/identifier>
"rdftk_core" .
<http://crates.io/crates/rdftk_core>
<http://purl.org/dc/terms/version>
"0.1.10" .
To allow the transport of this graph identifier the N-Triples language has been extended into N-Quads by allowing for an optional IRI or blank node as the fourth element in a serialized statement.
<http://crates.io/crates/rdftk_core>
<http://purl.org/dc/terms/identifier>
"rdftk_core"
<https://crates.io/rdf/crates/> .
<http://crates.io/crates/rdftk_core>
<http://purl.org/dc/terms/version>
"0.1.10"
<https://crates.io/rdf/crates/> .
Similarly, the Turtle language has been extended into TriG which defines a syntax that wraps a set of statements in braces preceded by a graph identifier.
@prefix dcterms: <http://purl.org/dc/terms/> .
<https://crates.io/rdf/crates/>
{
<http://crates.io/crates/rdftk_core>
dcterms:identifier "rdftk_core" ;
dcterms:version "0.1.10" ;
}
RDF*
RDF*, or RDF-star, is an effort to make the reification of statements more ergonomic in RDF. The current specification has been implemented by a number of frameworks, including RDFtk, and allows for an entire statement to be written in-line in representations such as Turtle, and expressed directly in SPARQL.
For example, the following is a textual representation of our “Joe said...“ reification example.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix : <#> .
_:S1
a rdf:Statement ;
rdf:subject :Jane ;
rdf:predicate :said ;
rdf:object "something" .
:Joe :said _:S1 .
Turtle does however have a short-cut for the representation of the blank node _:S1 above, which does make the
example somewhat more readable, but still verbose.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix : <#> .
:Joe
:said [
a rdf:Statement ;
rdf:subject :Jane ;
rdf:predicate :said ;
rdf:object "something"
] .
RDF* allows the inner statement to be included directly by enclosed within “<<“ and “>>”, as shown below.
:Joe :said << :Jane :said "something" >> .
Toolkit Overview
Toolkit Crates
The following lists the set of crates currently included in this repository (and Rust workspace), they are not yet complete and will probably be joined by others over time.
This crate provides the core RDF data model; concrete implementations for
Statements and Literals, along with a Resource type that provides a builder-like experience for models.
This crate provides traits for reading and writing
Statements and Graphs as well as implementations of these for common representations.
This crate provides an implementation of the
IRI and URI specifications.
This crate provides an implementation of the
Graph traits from rdftk_core::graph for simple in-memory usage.
This crate provides a set of modules that contain the
IRIs and QName strings for commonly used vocabularies. It also provides macro support for defining new namespaces in the same style as this library.
This crate provides a data model for creating ontologies using RDF Schema and OWL 2 Web Ontology Language (OWL).
This crate provides a placeholder for a query APIs and the SPARQL Query Language for RDF support.
A data model with RDF support for the Simple Knowledge Organization System (SKOS) vocabulary.
The figure below shows the dependencies between the crates.
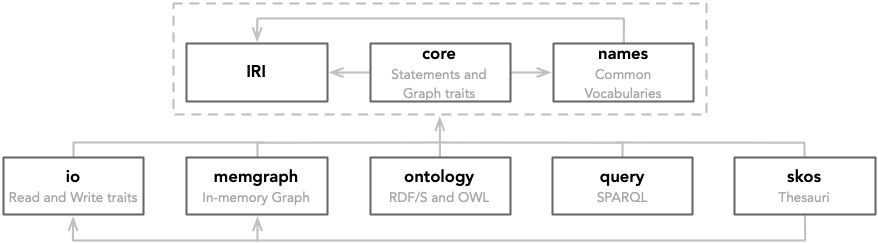
Core Data Model
Graph Serialization
Traits for reading/writing Statements and Graphs as well as implementations for common file
formats.
The following are some well-known formats (see Wikipedia
for a description of different serializations), support is indicated in the final column with
an R for read support and W for write support. One additional module, dot allows for the
creation of GraphViz dot files for a visualization of a graph’s structure.
| Module | Name | MIME Type | Specification | R/W |
|---|---|---|---|---|
nt | N-Triples | application/n-triples | W3C | W |
nq | N-Quads | application/n-quads | W3C | W |
n3 | N3 | text/rdf+n3 | W3C Submission | |
turtle | Turtle | text/turtle | W3C | W |
xml | RDF/XML | application/rdf+xml | W3C | |
json | JSON-LD | application/ld+json | W3C | |
| TBD | RDFa | text/html | W3C | |
| TBD | RDF/JSON | application/rdf+json | W3C | |
| TBD | TriG | application/trig | W3C | |
| TBD | HDT | ? | W3C Submission | |
| TBD | BinaryRDF | application/x-binary-rdf | Community |
Each module will also provide public constants NAME, FILE_EXTENSION, and MIME_TYPE.
IRI Implementation
rdftk_iri_specs
In-Memory Graph Implementation
Common Vocabularies
This crate provides a set of modules that contain the IRIs and QName strings for commonly used vocabularies. It also provides macro support for defining new namespaces in the same style as this library.
The vocabularies supported can be found below.
Macro Example
The following example replicates the geo module using the namespace! macro. Note that as this
macro uses paste::item the client will need to have a dependency on the
paste crate.
#[macro_use]
extern crate paste;
#[macro_use]
extern crate rdftk_names;
use rdftk_names::Vocabulary;
namespace! {
GeoSpatialVocabulary,
"geo",
"http://www.w3.org/2003/01/geo/wgs84_pos#",
{
spatial_thing, "SpatialThing",
temporal_thing, "TemporalThing",
event, "Event",
point, "Point",
lat, "lat",
location, "location",
long, "long",
alt, "alt",
lat_long, "lat_long"
}
}